publications
You may also want to check out my Google Scholar page.
2025
- William BrannonMIT, May 2025
Real-time social media platforms now host the news cycle and shape public opinion, while large language models (LLMs) give us new tools to observe and predict those shifts. This dissertation links the new affordances of social media with the predictive power of LLMs to explain – and forecast – opinion change. We first quantify the dynamics of news on an influential social platform, then develop LLM-based tools to forecast persuasion and predict heterogeneous treatment effects (HTEs). Study I — Media tempo and tone. Using 518,000 hours of U.S. talk-radio broadcasts and 26.6 million tweets from elite and mass users, we show that Twitter discourse (i) moves faster at both take-off and fade-out stages of a news event and (ii) sustains greater outrage than radio – despite radio’s often explicitly outrage-focused business model. To our knowledge, this is the first large-scale, data-driven comparison between Twitter and traditional media of both outrage levels and the rate of decay of attention to news. Study II — Zero-shot persuasion forecasting. Across a diverse set of 28 randomized experiments, LLM-based methods outperform an ensemble of strong baselines at predicting HTEs and deliver good performance at predicting average treatment effects (ATEs) — all without any experiment-specific fine-tuning. Study III — Transfer and scaling. Fine-tuning LLMs on contemporaneous news coverage boosts HTE (and ATE) prediction performance greatly, to more than 3x baseline performance. A new minibatch-moment-matching (M3) objective lets us train a 400M-parameter model to nearly match the HTE prediction performance of an 8B model at a fraction of the inference cost. Transfer, however, falters out of distribution on held-out experiments and demographic groups, lending support to contextual theories of persuasion. Overall, we (i) quantify how platform affordances shape the tone and tempo of public discourse, (ii) introduce LLM-based methods that make causal experiments more sample-efficient, and (iii) chart the limits of transfer learning for opinion prediction. Our findings provide practical tools for HTE prediction and help researchers anticipate persuasion dynamics in a media landscape shaped by both humans and machines.
@phdthesis{brannonLanguageModelsOpinion2025, title = {Language Models as Opinion Models: Techniques and Applications}, shorttitle = {Language Models as Opinion Models}, author = {Brannon, William}, address = {Cambridge, Massachusetts, USA}, school = {Massachusetts Institute of Technology}, date = {2025-05-29}, year = {2025}, month = may, url = {https://dspace.mit.edu/handle/1721.1/164147} } - Shayne Longpre, Nikhil Singh, Manuel Cherep, Kushagra Tiwary, Joanna Materzynska, William Brannon, 33 more authorsRobert Mahari, Manan Dey, Mohammed Hamdy, Nayan Saxena, Ahmad Mustafa Anis, Emad A. Alghamdi, Vu Minh Chien, Naana Obeng-Marnu, Da Yin, Kun Qian, Yizhi Li, Minnie Liang, An Dinh, Shrestha Mohanty, Deividas Mataciunas, Tobin South, Jianguo Zhang, Ariel N. Lee, Campbell S. Lund, Christopher Klamm, Damien Sileo, Diganta Misra, Enrico Shippole, Kevin Klyman, Lester JV Miranda, Niklas Muennighoff, Seonghyeon Ye, Seungone Kim, Vipul Gupta, Vivek Sharma, Xuhui Zhou, Caiming Xiong, Luis Villa, Stella Biderman, Alex Pentland, Sara Hooker, Jad KabbaraICLR, Apr 2025
Progress in AI is driven largely by the scale and quality of training data. Despite this, there is a deficit of empirical analysis examining the attributes of well-established datasets beyond text. In this work we conduct the largest and first-of-its-kind longitudinal audit across modalities–popular text, speech, and video datasets–from their detailed sourcing trends and use restrictions to their geographical and linguistic representation. Our manual analysis covers nearly 4000 public datasets between 1990-2024, spanning 608 languages, 798 sources, 659 organizations, and 67 countries. We find that multimodal machine learning applications have overwhelmingly turned to web-crawled, synthetic, and social media platforms, such as YouTube, for their training sets, eclipsing all other sources since 2019. Secondly, tracing the chain of dataset derivations we find that while less than 33% of datasets are restrictively licensed, over 80% of the source content in widely-used text, speech, and video datasets, carry non-commercial restrictions. Finally, counter to the rising number of languages and geographies represented in public AI training datasets, our audit demonstrates measures of relative geographical and multilingual representation have failed to significantly improve their coverage since 2013. We believe the breadth of our audit enables us to empirically examine trends in data sourcing, restrictions, and Western-centricity at an ecosystem-level, and that visibility into these questions are essential to progress in responsible AI. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire multimodal audit, allowing practitioners to trace data provenance across text, speech, and video.
@inproceedings{longpreBridgingDataProvenance2025, title = {Bridging the Data Provenance Gap Across Text, Speech and Video}, shorttitle = {Bridging the Data Provenance Gap}, booktitle = {Proceedings of the 13th International Conference on Learning Representations (ICLR '25)}, author = {Longpre, Shayne and Singh, Nikhil and Cherep, Manuel and Tiwary, Kushagra and Materzynska, Joanna and Brannon, William and Mahari, Robert and Dey, Manan and Hamdy, Mohammed and Saxena, Nayan and Anis, Ahmad Mustafa and Alghamdi, Emad A. and Chien, Vu Minh and {Obeng-Marnu}, Naana and Yin, Da and Qian, Kun and Li, Yizhi and Liang, Minnie and Dinh, An and Mohanty, Shrestha and Mataciunas, Deividas and South, Tobin and Zhang, Jianguo and Lee, Ariel N. and Lund, Campbell S. and Klamm, Christopher and Sileo, Damien and Misra, Diganta and Shippole, Enrico and Klyman, Kevin and Miranda, Lester JV and Muennighoff, Niklas and Ye, Seonghyeon and Kim, Seungone and Gupta, Vipul and Sharma, Vivek and Zhou, Xuhui and Xiong, Caiming and Villa, Luis and Biderman, Stella and Pentland, Alex and Hooker, Sara and Kabbara, Jad}, date = {2025-04-24}, year = {2025}, month = apr, primaryclass = {cs}, archiveprefix = {arXiv}, url = {https://openreview.net/forum?id=G5DziesYxL} }

2024
- Shayne Longpre, Robert Mahari, Ariel Lee, Campbell Lund, Hamidah Oderinwale, William Brannon, 39 more authorsNayan Saxena, Naana Obeng-Marnu, Tobin South, Cole Hunter, Kevin Klyman, Christopher Klamm, Hailey Schoelkopf, Nikhil Singh, Manuel Cherep, Ahmad Anis, An Dinh, Caroline Chitongo, Da Yin, Damien Sileo, Deividas Mataciunas, Diganta Misra, Emad Alghamdi, Enrico Shippole, Jianguo Zhang, Joanna Materzynska, Kun Qian, Kush Tiwary, Lester Miranda, Manan Dey, Minnie Liang, Mohammed Hamdy, Niklas Muennighoff, Seonghyeon Ye, Seungone Kim, Shrestha Mohanty, Vipul Gupta, Vivek Sharma, Vu Minh Chien, Xuhui Zhou, Yizhi Li, Caiming Xiong, Luis Villa, Stella Biderman, Hanlin Li, Daphne Ippolito, Sara Hooker, Jad Kabbara, Sandy PentlandNeurIPS, Dec 2024
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, large-scale, longitudinal audit of the consent protocols for the web domains underlying AI training corpora. Our audit of 14,000 web domains provides an expansive view of crawlable web data and how codified data use preferences are changing over time. We observe a proliferation of AI-specific clauses to limit use, acute differences in restrictions on AI developers, as well as general inconsistencies between websites’ expressed intentions in their Terms of Service and their robots.txt. We diagnose these as symptoms of ineffective web protocols, not designed to cope with the widespread re-purposing of the internet for AI. Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering 5%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose AI systems. We hope to illustrate the emerging crises in data consent, for both developers and creators. The foreclosure of much of the open web will impact not only commercial AI, but also non-commercial AI and academic research.
@inproceedings{longpreConsentCrisisRapid2024, title = {Consent in Crisis: The Rapid Decline of the {AI} Data Commons}, shorttitle = {Consent in Crisis}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS '24)}, author = {Longpre, Shayne and Mahari, Robert and Lee, Ariel and Lund, Campbell and Oderinwale, Hamidah and Brannon, William and Saxena, Nayan and {Obeng-Marnu}, Naana and South, Tobin and Hunter, Cole and Klyman, Kevin and Klamm, Christopher and Schoelkopf, Hailey and Singh, Nikhil and Cherep, Manuel and Anis, Ahmad and Dinh, An and Chitongo, Caroline and Yin, Da and Sileo, Damien and Mataciunas, Deividas and Misra, Diganta and Alghamdi, Emad and Shippole, Enrico and Zhang, Jianguo and Materzynska, Joanna and Qian, Kun and Tiwary, Kush and Miranda, Lester and Dey, Manan and Liang, Minnie and Hamdy, Mohammed and Muennighoff, Niklas and Ye, Seonghyeon and Kim, Seungone and Mohanty, Shrestha and Gupta, Vipul and Sharma, Vivek and Chien, Vu Minh and Zhou, Xuhui and Li, Yizhi and Xiong, Caiming and Villa, Luis and Biderman, Stella and Li, Hanlin and Ippolito, Daphne and Hooker, Sara and Kabbara, Jad and Pentland, Sandy}, editor = {Globerson, A. and Mackey, L. and Belgrave, D. and Fan, A. and Paquet, U. and Tomczak, J. and Zhang, C.}, pages = {108042--108087}, volume = {37}, publisher = {Curran Associates, Inc.}, date = {2024-12-11}, year = {2024}, month = dec, primaryclass = {cs}, archiveprefix = {arXiv}, url = {https://openreview.net/forum?id=66PcEzkf95} } - Suyash Fulay, William Brannon, Shrestha Mohanty, Cassandra Overney, Elinor Poole-Dayan, Deb Roy, and Jad KabbaraEMNLP, Nov 2024
Language model alignment research often attempts to ensure that models are not only helpful and harmless, but also truthful and unbiased. However, optimizing these objectives simultaneously can obscure how improving one aspect might impact the others. In this work, we focus on analyzing the relationship between two concepts essential in both language model alignment and political science: truthfulness and political bias. We train reward models on various popular truthfulness datasets and subsequently evaluate their political bias. Our findings reveal that optimizing reward models for truthfulness on these datasets tends to result in a left-leaning political bias. We also find that existing open-source reward models (i.e. those trained on standard human preference datasets) already show a similar bias and that the bias is larger for larger models. These results raise important questions about both the datasets used to represent truthfulness and what language models capture about the relationship between truth and politics.
@inproceedings{fulayRelationshipTruthPolitical2024, title = {On the Relationship between Truth and Political Bias in Language Models}, author = {Fulay, Suyash and Brannon, William and Mohanty, Shrestha and Overney, Cassandra and Poole-Dayan, Elinor and Roy, Deb and Kabbara, Jad}, booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing}, editor = {Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung}, pages = {9004--9018}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, date = {2024-11-12}, year = {2024}, month = nov, doi = {10.18653/v1/2024.emnlp-main.508}, primaryclass = {cs}, archiveprefix = {arXiv}, url = {https://aclanthology.org/2024.emnlp-main.508/} } - Hang Jiang, Doug Beeferman, William Brannon, Andrew Heyward, and Deb RoyCSCW, Nov 2024
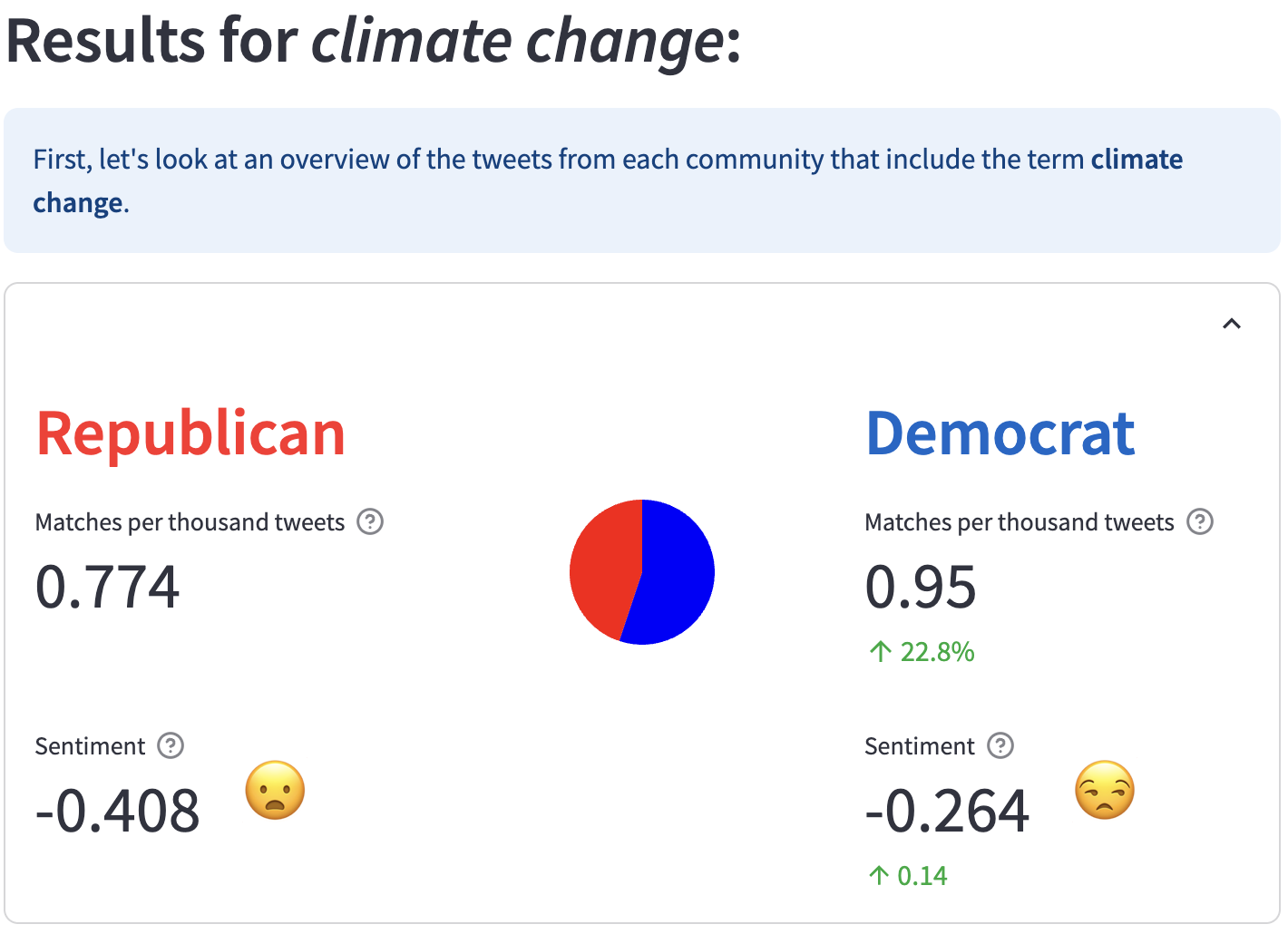
Words often carry different meanings for people from diverse backgrounds. Today’s era of social polarization demands that we choose words carefully to prevent miscommunication, especially in political communication and journalism. To address this issue, we introduce the Bridging Dictionary, an interactive tool designed to illuminate how words are perceived by people with different political views. The Bridging Dictionary includes a static, printable document featuring 796 terms with summaries generated by a large language model. These summaries highlight how the terms are used distinctively by Republicans and Democrats. Additionally, the Bridging Dictionary offers an interactive interface that lets users explore selected words, visualizing their frequency, sentiment, summaries, and examples across political divides. We present a use case for journalists and emphasize the importance of human agency and trust in further enhancing this tool. The deployed version of Bridging Dictionary is available at https://dictionary.ccc-mit.org/.
@inproceedings{jiangBridgingDictionaryAIGenerated2024, title = {Bridging Dictionary: {AI}-Generated Dictionary of Partisan Language Use}, booktitle = {{CSCW} Companion '24: Companion Publication of the 2024 Conference on Computer-Supported Cooperative Work and Social Computing}, author = {Jiang, Hang and Beeferman, Doug and Brannon, William and Heyward, Andrew and Roy, Deb}, pages = {79 --- 82}, publisher = {Association for Computing Machinery}, address = {San Jose, Costa Rica}, isbn = {979-8-4007-1114-5}, date = {2024-11-12}, year = {2024}, month = nov, doi = {10.1145/3678884.3681820}, primaryclass = {cs}, archiveprefix = {arXiv}, url = {https://dl.acm.org/doi/10.1145/3678884.3681820} } - William Brannon, Doug Beeferman, Hang Jiang, Andrew Heyward, and Deb RoyCSCW, Nov 2024
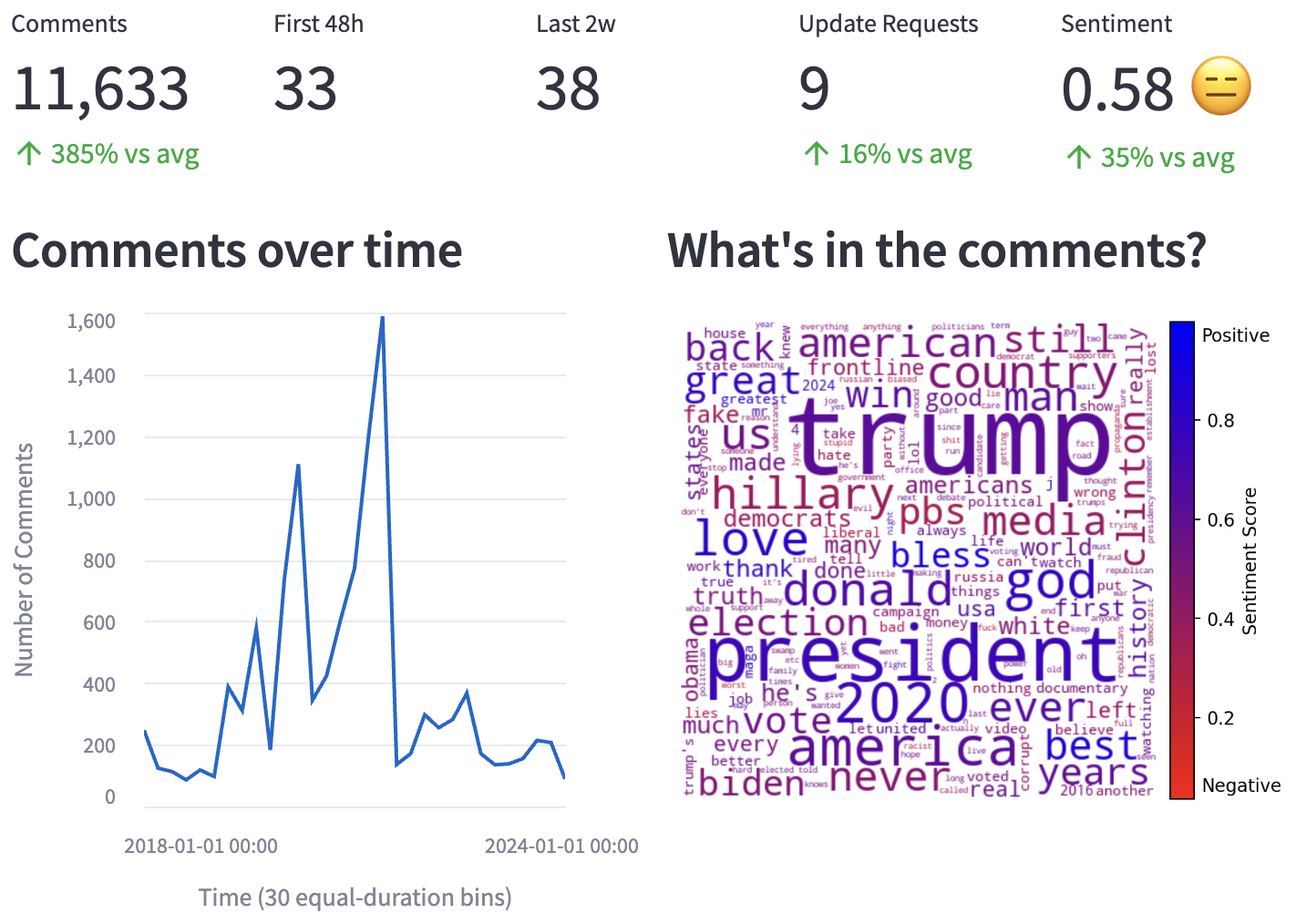
Understanding and making use of audience feedback is important but difficult for journalists, who now face an impractically large volume of audience comments online. We introduce AudienceView, an online tool to help journalists categorize and interpret this feedback by leveraging large language models (LLMs). AudienceView identifies themes and topics, connects them back to specific comments, provides ways to visualize the sentiment and distribution of the comments, and helps users develop ideas for subsequent reporting projects. We consider how such tools can be useful in a journalist’s workflow, and emphasize the importance of contextual awareness and human judgment.
@inproceedings{brannonAudienceViewAIAssistedInterpretation2024, title = {{A}udience{V}iew: {AI}-Assisted Interpretation of Audience Feedback in Journalism}, author = {Brannon, William and Beeferman, Doug and Jiang, Hang and Heyward, Andrew and Roy, Deb}, booktitle = {{CSCW} Companion '24: Companion Publication of the 2024 Conference on Computer-Supported Cooperative Work and Social Computing}, pages = {65 --- 68}, publisher = {Association for Computing Machinery}, address = {San Jose, Costa Rica}, isbn = {979-8-4007-1114-5}, date = {2024-11-12}, year = {2024}, month = nov, doi = {10.1145/3678884.3681821}, primaryclass = {cs}, archiveprefix = {arXiv}, url = {https://dl.acm.org/doi/10.1145/3678884.3681821} } - Shayne Longpre, Robert Mahari, Anthony Chen, Naana Obeng-Marnu, Damien Sileo, William Brannon, 7 more authorsNiklas Muennighoff, Nathan Khazam, Jad Kabbara, Kartik Perisetla, Xinyi Wu, Enrico Shippole, Kurt Bollacker, Tongshuang Wu, Luis Villa, Sandy Pentland, Sara HookerNature Machine Intelligence, Aug 2024
The race to train language models on vast, diverse, and inconsistently documented datasets raises pressing legal and ethical concerns. To improve data transparency and understanding, we convene a multi-disciplinary effort between legal and machine learning experts to systematically audit and trace 1,800+ text datasets. We develop tools and standards to trace the lineage of these datasets, including their source, creators, licenses, and subsequent use. Our landscape analysis highlights sharp divides in the composition and focus of data licensed for commercial use. Important categories including low resource languages, creative tasks, and novel synthetic data all tend to be restrictively licensed. We observe frequent miscategorization of licenses on popular dataset hosting sites, with license omission rates of 70%+ and error rates of 50%+. This highlights a crisis in misattribution and informed use of popular datasets driving many recent breakthroughs. Our analysis of data sources also elucidates the application of copyright law and fair use to finetuning data. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our audit, with an interactive UI, the Data Provenance Explorer, to enable practitioners to trace and filter on data provenance for the most popular finetuning data collections: www.dataprovenance.org.
@article{longpreLargeScaleAuditDataset2024, title = {A Large-Scale Audit of Dataset Licensing and Attribution in {AI}}, author = {Longpre, Shayne and Mahari, Robert and Chen, Anthony and {Obeng-Marnu}, Naana and Sileo, Damien and Brannon, William and Muennighoff, Niklas and Khazam, Nathan and Kabbara, Jad and Perisetla, Kartik and Wu, Xinyi and Shippole, Enrico and Bollacker, Kurt and Wu, Tongshuang and Villa, Luis and Pentland, Sandy and Hooker, Sara}, journal = {Nature Machine Intelligence}, volume = {6}, number = {8}, pages = {975--987}, publisher = {Nature Publishing Group}, date = {2024-08-30}, year = {2024}, month = aug, doi = {10.1038/s42256-024-00878-8}, primaryclass = {cs}, archiveprefix = {arXiv}, url = {https://www.nature.com/articles/s42256-024-00878-8} } - William Brannon, Suyash Fulay, Hang Jiang, Wonjune Kang, Brandon Roy, Deb Roy, and Jad KabbaraTextGraphs at ACL, Aug 2024
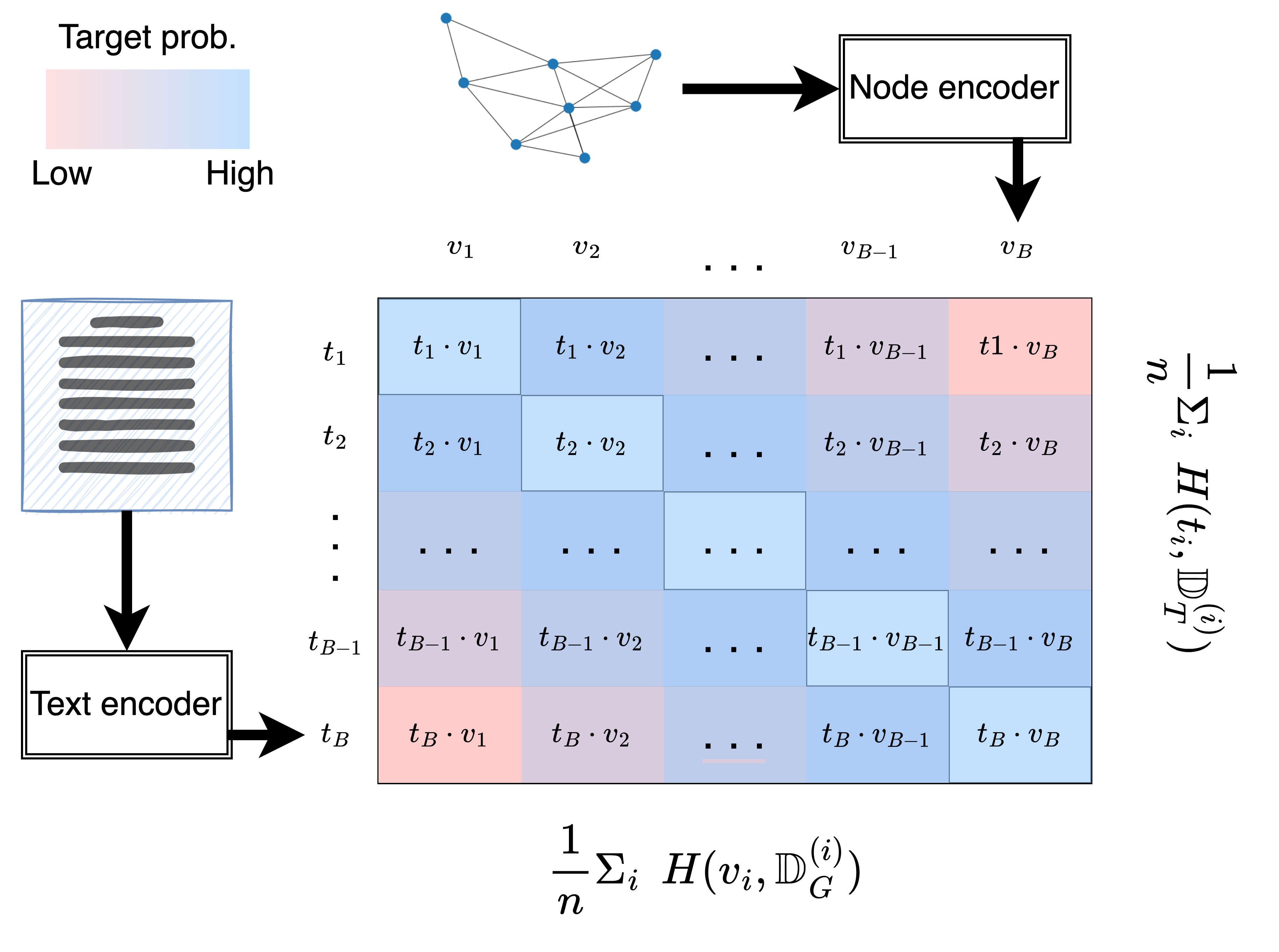
Learning on text-attributed graphs (TAGs), in which nodes are associated with one or more texts, has been the subject of much recent work. However, most approaches tend to make strong assumptions about the downstream task of interest, are reliant on hand-labeled data, or fail to equally balance the importance of both text and graph representations. In this work, we propose Contrastive Graph-Text pretraining (ConGraT), a general, self-supervised approach for jointly learning separate representations of texts and nodes in a TAG. Our method trains a language model (LM) and a graph neural network (GNN) to align their representations in a common latent space using a batch-wise contrastive learning objective inspired by CLIP. We further propose an extension to the CLIP objective that leverages graph structure to incorporate information about inter-node similarity. Extensive experiments demonstrate that ConGraT outperforms baselines on various downstream tasks, including node and text category classification, link prediction, and language modeling. Finally, we present an application of our method to community detection in social graphs, which enables finding more textually grounded communities, rather than purely graph-based ones. Code and certain datasets are available at https://github.com/wwbrannon/congrat.
@inproceedings{brannonConGraTSelfSupervisedContrastive2024, keywords = {workshop}, title = {{C}on{G}ra{T}: Self-Supervised Contrastive Pretraining for Joint Graph and Text Embeddings}, author = {Brannon, William and Fulay, Suyash and Jiang, Hang and Kang, Wonjune and Roy, Brandon and Roy, Deb and Kabbara, Jad}, booktitle = {Proceedings of the Seventeenth Workshop on Graph-Based Methods for Natural Language Processing ({T}ext{G}raphs-17)}, editor = {Ustalov, Dmitry and Gao, Yanjun and Panchenko, Alexander and Tutubalina, Elena and Nikishina, Irina and Ramesh, Arti and Sakhovskiy, Andrey and Usbeck, Ricardo and Penn, Gerald and Valentino, Marco}, pages = {19 --- 39}, publisher = {Association for Computational Linguistics}, address = {Bangkok, Thailand}, date = {2024-08-15}, year = {2024}, month = aug, primaryclass = {cs}, archiveprefix = {arXiv}, url = {https://aclanthology.org/2024.textgraphs-1.2} } - Shayne Longpre, Robert Mahari, Naana Obeng-Marnu, William Brannon, Tobin South, Katy Ilonka Gero, Alex Pentland, and Jad KabbaraICML, Jul 2024
Spotlight (top 3%)
New capabilities in foundation models are owed in large part to massive, widely-sourced, and under-documented training data collections. Existing practices in data collection have led to challenges in tracing authenticity, verifying consent, preserving privacy, addressing representation and bias, respecting copyright, and overall developing ethical and trustworthy foundation models. In response, regulation is emphasizing the need for training data transparency to understand foundation models’ limitations. Based on a large-scale analysis of the foundation model training data landscape and existing solutions, we identify the missing infrastructure to facilitate responsible foundation model development practices. We examine the current shortcomings of common tools for tracing data authenticity, consent, and documentation, and outline how policymakers, developers, and data creators can facilitate responsible foundation model development by adopting universal data provenance standards.
@inproceedings{longprePositionDataAuthenticity2024, title = {Position: Data Authenticity, Consent, \& Provenance for {AI} Are All Broken: What Will It Take to Fix Them?}, booktitle = {Proceedings of the 41st International Conference on Machine Learning}, author = {Longpre, Shayne and Mahari, Robert and {Obeng-Marnu}, Naana and Brannon, William and South, Tobin and Gero, Katy Ilonka and Pentland, Alex and Kabbara, Jad}, publisher = {PMLR}, address = {Vienna, Austria}, date = {2024-07-21}, year = {2024}, month = jul, primaryclass = {cs}, archiveprefix = {arXiv}, url = {https://proceedings.mlr.press/v235/longpre24b.html} } - William Brannon and Deb RoyScientific Reports, May 2024
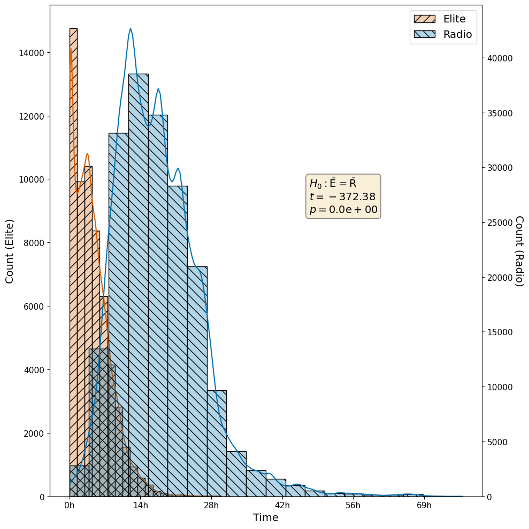
The rapid evolution of the Internet is reshaping the media landscape, with frequent claims of an accelerated and increasingly outraged news cycle. We test these claims empirically, investigating the dynamics of news spread, decay, and sentiment on Twitter (now known as X) compared to talk radio. Analyzing 2019–2021 data including 517,000 hour of radio content and 26.6 million tweets by elite journalists, politicians, and general users, we identified 1694 news events. We find that news on Twitter circulates faster, fades faster, and is more negative and outraged compared to radio, with Twitter outrage also more short-lived. These patterns are consistent across various user types and robustness checks. Our results illustrate an important way social media may influence traditional media: framing and agenda-setting simply by speaking first. As journalism evolves with these media, news audiences may encounter faster shifts in focus, less attention to each news event, and much more negativity and outrage.
@article{brannonSpeedNewsTwitter2024, title = {The Speed of News in {T}witter ({X}) versus Radio}, author = {Brannon, William and Roy, Deb}, journal = {Scientific Reports}, volume = {14}, number = {1}, pages = {11939}, publisher = {Nature Publishing Group}, date = {2024-05-24}, year = {2024}, month = may, doi = {10.1038/s41598-024-61921-7}, url = {https://www.nature.com/articles/s41598-024-61921-7} }

2023
- GenLaw
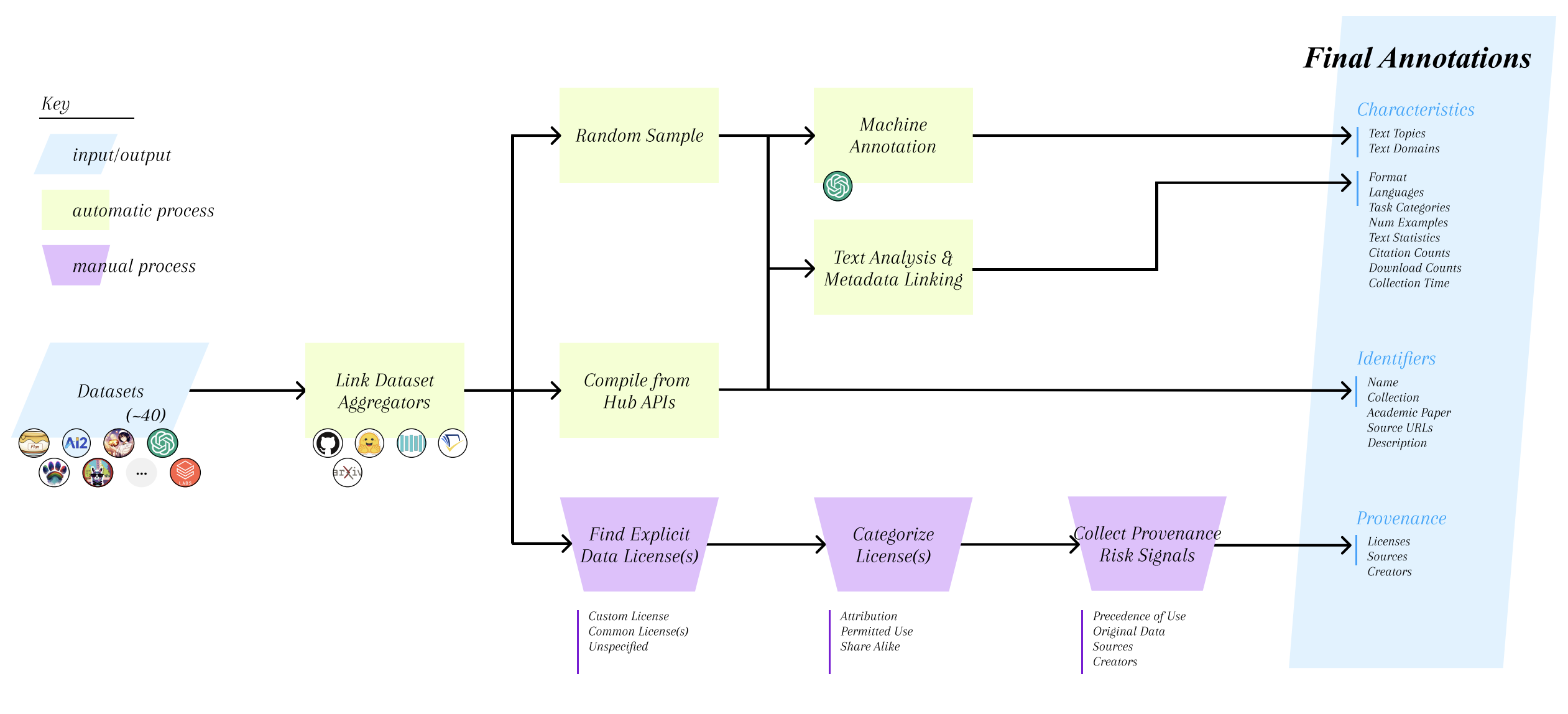 Shayne Longpre, Robert Mahari, Niklas Muennighoff, Anthony Chen, Kartik Perisetla, William Brannon, Jad Kabbara, Luis Villa, and Sara HookerGenLaw at ICML, Jul 2023
Shayne Longpre, Robert Mahari, Niklas Muennighoff, Anthony Chen, Kartik Perisetla, William Brannon, Jad Kabbara, Luis Villa, and Sara HookerGenLaw at ICML, Jul 2023Spotlight paper
A wave of recent language models have been powered by large collections of natural language datasets. The sudden race to train models on these disparate collections of incorrectly, ambiguously, or under-documented datasets has left practitioners unsure of the legal and qualitative characteristics of the models they train. To remedy this crisis in data transparency and understanding, in a joint effort between experts in machine learning and the law, we’ve compiled the most detailed and reliable metadata available for data licenses, sources, and provenance, as well as fine-grained characteristics like language, text domains, topics, usage, collection time, and task compositions. Beginning with nearly 40 popular instruction (or "alignment") tuning collections, we release a suite of open source tools for downloading, filtering, and examining this training data. Our analysis sheds light on the fractured state of data transparency, particularly with data licensing, and we hope our tools will empower more informed and responsible data-centric development of future language models.
@inproceedings{longpreDataProvenanceProject2023, keywords = {workshop}, title = {The Data Provenance Project}, booktitle = {Proceedings of the 40th International Conference on Machine Learning}, booksubtitle = {1st Workshop on Generative AI and Law ({G}en{L}aw '23)}, author = {Longpre, Shayne and Mahari, Robert and Muennighoff, Niklas and Chen, Anthony and Perisetla, Kartik and Brannon, William and Kabbara, Jad and Villa, Luis and Hooker, Sara}, address = {Honolulu, Hawaii, USA}, date = {2023-07-23}, year = {2023}, month = jul, url = {https://blog.genlaw.org/CameraReady/20.pdf} } - William Brannon, Yogesh Virkar, and Brian ThompsonTACL, May 2023
We investigate how humans perform the task of dubbing video content from one language into another, leveraging a novel corpus of 319.57 hours of video from 54 professionally produced titles. This is the first such large-scale study we are aware of. The results challenge a number of assumptions commonly made in both qualitative literature on human dubbing and machine-learning literature on automatic dubbing, arguing for the importance of vocal naturalness and translation quality over commonly emphasized isometric (character length) and lip-sync constraints, and for a more qualified view of the importance of isochronic (timing) constraints. We also find substantial influence of the source-side audio on human dubs through channels other than the words of the translation, pointing to the need for research on ways to preserve speech characteristics, as well as transfer of semantic properties such as emphasis and emotion, in automatic dubbing systems.
@article{brannonDubbingPracticeLarge2023, title = {Dubbing in Practice: A Large-Scale Study of Human Localization With Insights for Automatic Dubbing}, shorttitle = {Dubbing in Practice}, author = {Brannon, William and Virkar, Yogesh and Thompson, Brian}, journal = {Transactions of the Association for Computational Linguistics}, volume = {11}, pages = {419--435}, shortjournal = {TACL}, date = {2023-05-11}, year = {2023}, month = may, doi = {10.1162/tacl_a_00551}, primaryclass = {cs}, archiveprefix = {arXiv}, url = {https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00551/115968/Dubbing-in-Practice-A-Large-Scale-Study-of-Human} }
2020
- William BrannonMIT, Aug 2020
This thesis attempts the first large-scale mapping of American talk radio, leveraging recently developed datasets of transcribed radio programs. We set out to explore the internal structure of this influential medium along three axes, reflecting a typology of the main social contexts in which it is embedded: its corporate ownership, its geographical location in the country and perhaps most importantly its relationship to the broader media ecosystem, operationalized through Twitter. The results depict a radio ecosystem operating in a mostly centralized way. In talk radio, station ownership, usually by large publicly traded companies, is the strongest correlate of cosine similarity in the stations’ distributions of airtime to shows; in public radio, the greater similarity of these airtime distributions medium-wide than in talk radio reflects the influence of centralized, nationwide syndication networks like NPR. The distribution of important topics of political discussion is also surprisingly similar across stations. Geography plays relatively little role, with programming and topics varying little along geographic lines. Despite these centralizing tendencies, local radio is not extinct even on large corporate stations, and is meaningfully local in content as well as production. Local programs have lower average cosine similarities between their topic mixtures than syndicated ones do, demonstrating a greater diversity of discussion topics and perhaps perspectives. These shows are also more in touch with local opinion, in that models trained on their text better predict the partisan lean of their listeners than is true of syndicated radio. But syndication makes up the large majority of stations’ airtime. Moving to the third of our three axes, radio reflects the same underlying social structure as Twitter, and this structure is reflected in the content of broadcasts. We examined the relationship by comparing radio to a set of highly followed and influential journalists and politicians. The influential Twitter users manifest a similar social structure to radio: graph communities and a measure of latent ideology extracted from the follow graph fit radio’s offline structure well; more directly, the follow graph itself and the "co-airing graph" (between shows, in which two shows are connected if they air on the same station) are quite similar. Moreover, this common social structure is predictable from the text of radio shows. The contents of Twitter and radio are also closely linked, with hosts discussing a similar mix of topics on both platforms. A case study of President Trump’s tweets reveals their probable causal effects on radio discussion, though other evidence of direct influence from Twitter is much more limited. The American talk radio ecosystem, as revealed here, while still partly local in character, is an integral part of the national media ecosystem and best understood in that context.
@mastersthesis{brannonMappingTalkRadio2020, title = {Mapping {U.S.} Talk Radio: A Textual Survey at Scale}, shorttitle = {Mapping {U.S.} Talk Radio}, author = {Brannon, William}, address = {Cambridge, Massachusetts, USA}, school = {Massachusetts Institute of Technology}, date = {2020-08-17}, year = {2020}, month = aug, url = {https://dspace.mit.edu/handle/1721.1/129270} }
2019
- Doug Beeferman, William Brannon, and Deb RoyInterspeech, Sep 2019
We introduce RadioTalk, a corpus of speech recognition transcripts sampled from talk radio broadcasts in the United States between October of 2018 and March of 2019. The corpus is intended for use by researchers in the fields of natural language processing, conversational analysis, and the social sciences. The corpus encompasses approximately 2.8 billion words of automatically transcribed speech from 284,000 hours of radio, together with metadata about the speech, such as geographical location, speaker turn boundaries, gender, and radio program information. In this paper we summarize why and how we prepared the corpus, give some descriptive statistics on stations, shows and speakers, and carry out a few high-level analyses.
@inproceedings{beefermanRadioTalkLargeScaleCorpus2019, title = {{RadioTalk}: A Large-Scale Corpus of Talk Radio Transcripts}, shorttitle = {{R}adio{T}alk}, author = {Beeferman, Doug and Brannon, William and Roy, Deb}, booktitle = {Proceedings of {I}nterspeech}, pages = {564--568}, publisher = {ISCA}, address = {Graz, Austria}, date = {2019-09-16}, year = {2019}, month = sep, doi = {10.21437/Interspeech.2019-2714}, primaryclass = {cs}, archiveprefix = {arXiv}, url = {https://www.isca-archive.org/interspeech_2019/beeferman19_interspeech.html} }
